
Can We Achieve 100% Accurate Data Extraction From Complex Documents With LLMs?
Extracting structured data from various document sources comes with a set challenges. Documents come in many forms, such as PDFs, scanned images, and native text, making it tricky to pull out normalized information. Once the data is extracted, it must be organized into a clear structure that machines can process reliably. Normalizing complex data into system readable formats often requires the use of Large Language Models (LLMs).
Another challenge is dealing with many variations of the same document type. For instance, invoices, NDAs, and resumes often have completely different layouts and formats. To tackle this, we need flexible LLM prompts that work across these variations and adapt quickly to new types of documents.
But even LLMs aren't perfect. Sometimes they produce inaccurate results. That’s why automated checks are essential to ensure the data is trustworthy - simply relying on manual evaluations can be slow and prone to errors. This article will focus on how to create structured, machine-readable data from unstructured document sources while ensuring output accuracy.
Steps for Optimizing Complex Document Data Extraction
Use Multiple Passes with LLMs. Break down the document extraction process into distinct phases, each focused on extracting specific goals such as recognizing entities, establishing entity relationships, and handling special tabular data sets such as charts or financials. By iteratively refining the results with multiple passes, you can significantly enhance accuracy.
Deploy Multiple Agents for Quality Consensus. Run the same document through multiple LLMs or configurations and compare their outputs. This approach leverages the strengths of different models, helping you assess data consistency and pinpoint discrepancies. A similar approach is to implement design-specialized LLM agents trained to verify specific types of extracted data. These agents can validate key elements or perform sanity checks, ensuring the extracted data meets quality standards. We've found that implementing a consensus strategy for QC reduces the chance of error to .0001%.
Multi-Pass LLM
Key aspects of a multi-pass LLM structured data extraction process:
Initial Pass: Entity Recognition: The first pass might primarily identify key entities like names, dates, locations, and organizations within the text, providing a basic understanding of the document's content.
Subsequent Passes: Relationship Extraction: Following the initial pass, the LLM could focus on extracting relationships between identified entities, such as "Company X is located in City Y" or "Person A is employed by Organization Z" by analyzing context and surrounding text in each section of the document.
Context-Aware Analysis: Each pass can leverage the information gathered in previous passes to refine its understanding of the context and make more accurate extractions, especially when dealing with ambiguous or nuanced information.
Adaptive Prompts: The prompts given to the LLM in each pass can be tailored based on the extraction goal, allowing the model to focus on specific data points or relationships during each iteration.
Benefits of a Multi-Pass Approach:
Improved Accuracy: By examining the text multiple times with different focuses, the LLM can better identify and extract complex relationships between data points, leading to more accurate structured data output.
Handling Complex Documents: Particularly useful for documents with intricate structures or where information is spread across various sections, as the multi-pass strategy allows the LLM to piece together the data from different parts of the document.
Flexibility: Depending on the specific needs of the extraction task, the number of passes and the focus of each pass can be adjusted to optimize the results.
Challenges to Consider:
Computational Cost: Performing multiple passes through the text can increase processing time and incur additional LLM cost, especially for large documents.
Prompt Engineering: Designing effective prompts for each pass is crucial to guide the LLM towards the desired information extraction goals.
Chunking: LLMs have limited token windows, limiting the amount of input data and output responses, so a large document need to be broken down into smaller logical chunks using markers like a section header.
Example Applications:
Extracting information from legal documents: A first pass might identify key entities like parties, dates, and contract terms. Subsequent passes would then focus on extracting the relationships between these entities, such as the obligations of each party or the specific terms of the agreement
Extracting information from insurance policy documents: A first pass might extract top level plan specific information such as plan id, eligibility, and other summarized plan overview. Subsequent passes focus on extracting plan specific data such as user co-pay structures, benefit packages, participant information, and policy terms.
Consensus-Driven Quality Checks
LLMs can work really well for document data extraction use cases. The trouble with them however, is that they can hallucinate. And worse, there is no reliably way to detect if an LLM has indeed hallucinated and provided inaccurate extractions. If LLMs are to be deployed in production for at-scale use cases, users need to be sure that there are no hallucinations happening. Wrong extractions undermine trust in the system.
One effective way to mitigate hallucination risks is by employing consensus-driven quality checks. This involves running the same document through multiple LLMs or configurations and comparing their outputs. When multiple models arrive at the same result, it increases confidence in the accuracy of the extraction. Conversely, significant discrepancies between outputs can signal potential issues and highlight the need for further investigation.
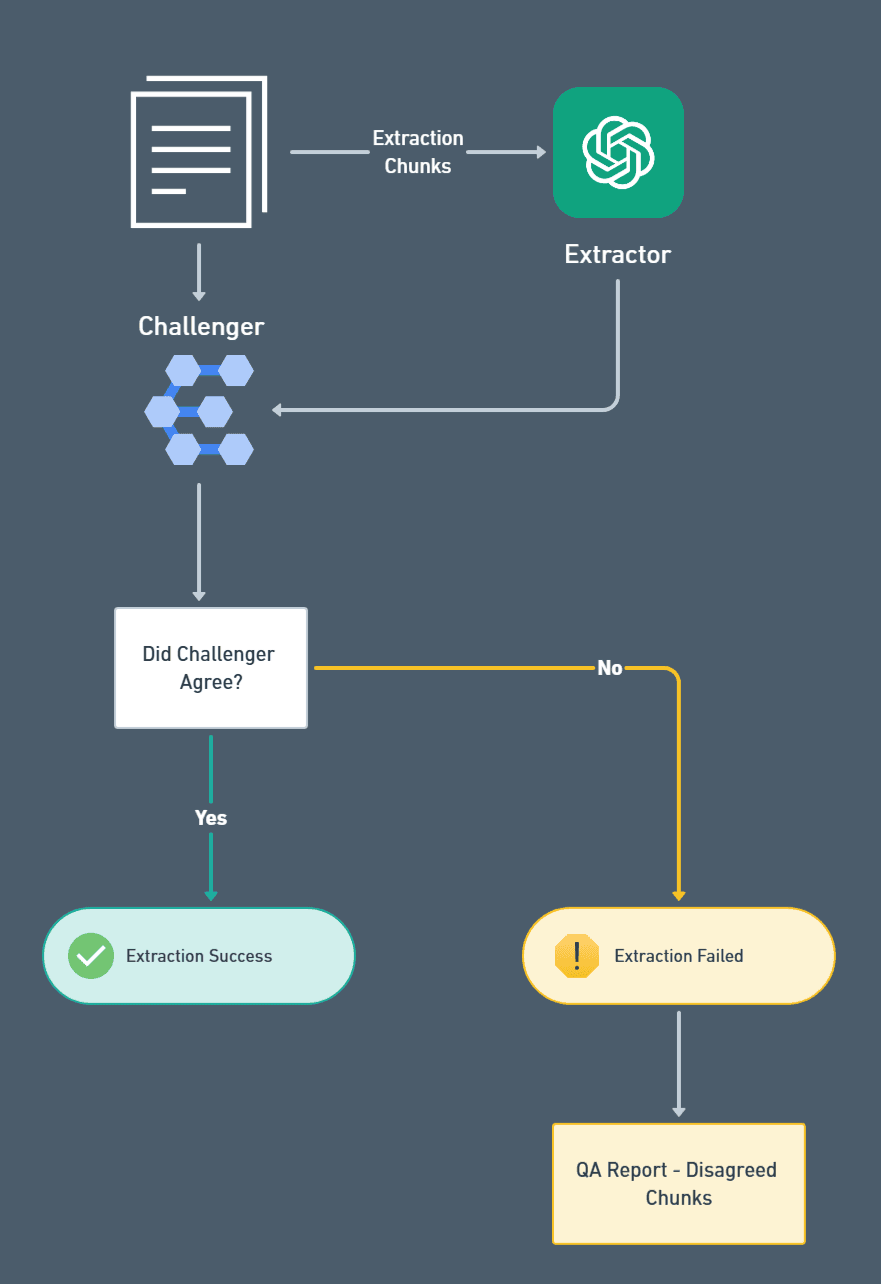
To implement this, we set up a pipeline where:
Diverse Models or Configurations: Use different LLMs, such as GPT variants or fine-tuned models, to process the same input. This ensures a range of perspectives and minimizes reliance on a single model's output.
Automated Comparison Logic: Establish automated systems to compare the results of each model. Use algorithms to identify matches, flag outliers, and assess consensus levels.
Weighted Voting Mechanism: Assign weights to different models based on their historical performance or reliability for specific data types. Models with higher accuracy rates can carry more influence in the consensus process.
Human-in-the-Loop Validation: For high-priority or ambiguous cases, introduce human reviewers to cross-check flagged discrepancies. This adds an additional layer of assurance without requiring full manual evaluation of every document.
By using this consensus-driven approach, organizations can significantly reduce the risk of hallucinations and build more trust in their LLM-based systems. This means that the extracted data can be confidently used in downstream processes without manual rework.
Closing Thoughts
Extracting structured data from unstructured documents with perfect precision is no small feat, but with the right strategies, we can achieve perfect outputs. By leveraging approaches like multi-pass processing, consensus-driven quality checks, and adaptive prompt engineering, organizations can harness the power of LLMs while mitigating their limitations. Theary’s Intelligent Document Processing capabilities accelerate the path to perfect data extraction, our core platform is built around reliability, accuracy, and trust in these transformative technologies. info@theary.com

